TryHackMe | Content Discovery Walkthrough
Learn the various ways of discovering hidden or private content on a webserver that could lead to new vulnerabilities.
Link- https://tryhackme.com/room/contentdiscovery
What is the Content Discovery method that begins with M?
Manually
What is the Content Discovery method that begins with A?
Automated
What is the Content Discovery method that begins with O?
OSINT
What is the directory in the robots.txt that isn’t allowed to be viewed by web crawlers?
Check the robots.txt file
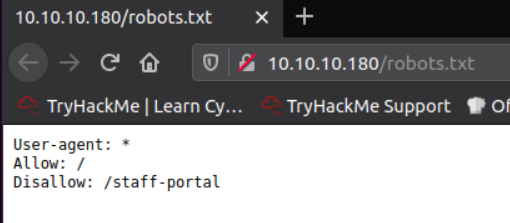
/staff-portal
What framework did the favicon belong to?
Download the file and upload to virustotal to get hash and then check the mentioned website for the hash.
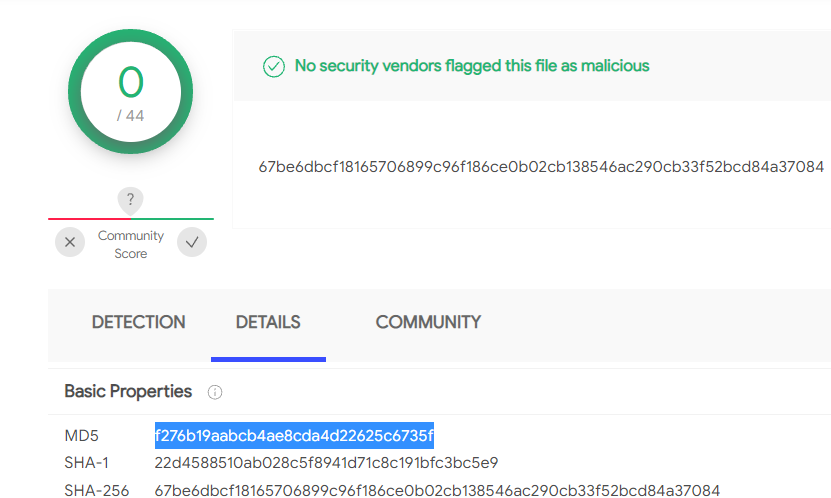
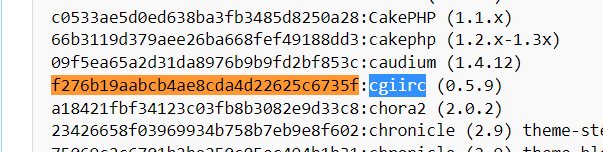
cgiirc
What is the path of the secret area that can be found in the sitemap.xml file?
Check the sitemap
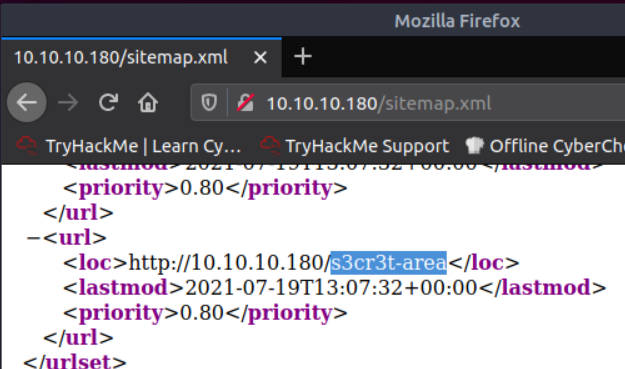
/s3cr3t-area
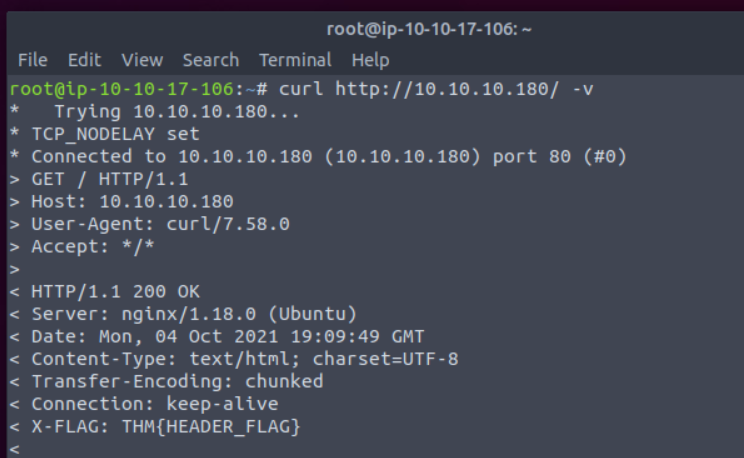
What is the flag value from the X-FLAG header?
Run the curl command
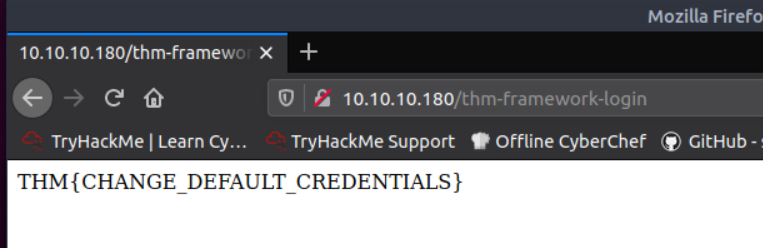
What is the flag from the framework’s administration portal?
Go to mentioned website and find the location /thm-framework-login and login with username and password “admin”
What Google dork operator can be used to only show results from a particular site?
site:
What online tool can be used to identify what technologies a website is running?
Wappalyzer
What is the website address for the Wayback Machine?
https://archive.org/web
What is Git?
version control system
What URL format do Amazon S3 buckets end in?
.s3.amazonaws.com
What is the name of the directory beginning “/mo….” that was discovered?
Run Gobuster
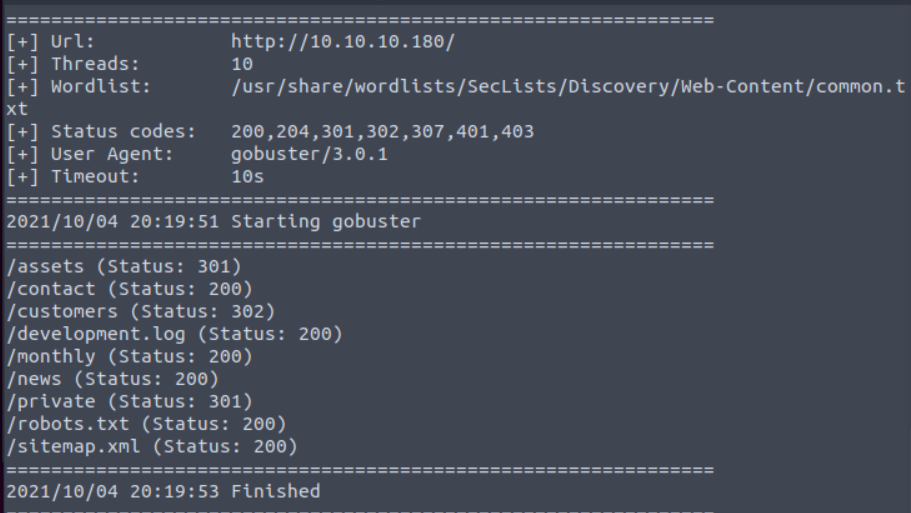
/monthly
What is the name of the log file that was discovered?
/development.log
That’s it. See you in the next room :)



Comments
Post a Comment